同是在船上做记号,刻舟求剑与曹冲称象的败与成。
作者的自序——《最后一层表象》——是读者同作者沟通的基石。我从作者的发问中,观照到了自己的影子……
我已有了“什么是程序?”的答案,而“我所追寻的是什么?”的答案又是什么呢?
文摘
“算”是程序之表,“数”是程序之本。
数据,并不是数,而是数的系列。数据,其内聚的特性表明它由一系列存有相互关系的数构成,其外延的特性表明它可以与其他数的系列建立新的抽象关系。数据性质的基本子集:标识、值和确定性。
因为不可能有永远的或者无尽的存储,所以任何在计算系统中的数据都存有生存周期的问题。我们讨论的确定与不确定是以其生存周期为背景的。数据一旦存在“不确定”的可能,则计算系统的严密性就受到了挑战——计算的不确定性是对机器计算是否有价值的终极拷问。
计算系统的要素包括:数、数据和逻辑,以及在此基础上进行正确计算的方法的抽象,即计算范式。
程序设计语言,是指计算机与人(亦即是程序的使用者与定义者)之间沟通的工具,其有着三种基本性质:语法、语义与语用。
所谓的“会编程”,是指将我们的意图表达为计算系统的理解能力范围内的语义。而这种语义与掌握某种语言的语法形式无关,它由计算系统与程序员共同确知的数据与逻辑构成,且最终可以由某种计算方法在指定计算系统上实施以得到计算结果。
在严格的计算系统中,语用——这一语言的背景因素被限制在计算机的初始环境中,从而使“语义+语法”能够描述确定的计算及其结果成为可能。
使用人群由专业人员变成普通用户,将导致提出大量的非功能需求,即它作为“软件”的使用问题;
由于使用人群的变化,维护和发布的工作对程序员变得不可控,因此将导致提出大量的非当前需求,即它作为“产品”的生命周期问题。
从计算机应用的历史来看,我们在语言中加入新的元素,其本质的原因正是旧的语言特性在应对规模(而非仅仅是计算)的时候显得力不从心,尤其是在应用与系统这两个规模级别中,(在语法与语义上的)语言特性体现出来的代码组织能力,相当大的程度上决定了这门语言所适用的开发规模。
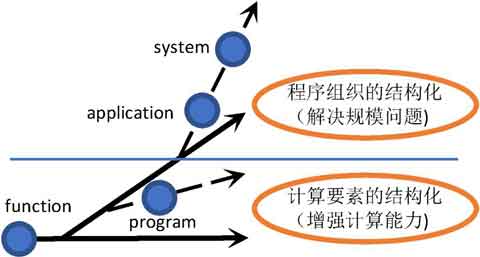
程序设计主要应对计算要素问题,产出是一般含义上的程序;应用开发主要应对程序组织问题,产出是有产品化概念的软件;系统构建主要应对跨领域问题,产出是可持续进化的系统。
数组指的是包括某种相同数据(数组元素的类型相同)的连续空间,是顺序地址存储这一概念的自然延伸。结构体指的就是包括某几种不同数据的连续空间,是对数组的补充。数组与结构体一起构成了“用基础数据类型”来复合其他类型的全部可能性。
指针是对顺序的结构化存储这一方案在运行期的一种补充。它是一个标识,有一个计算系统访问它的地址。它包含数据(值),该值是一个(与它关联的、实际的)数据的地址。
关联数组在基于地址存取的机器中应用时,面临的核心问题是:作为名字的字符串存在无限的组合,这与有限的地址空间是矛盾的。哈希算法通过将“名/值”映射为“Key/Code/Value”的关系,从而解决了上述问题。“名/值”数据系统与其存储背景有着相关大的关系,“必须在相同背景下创建与维护哈希表”是一种系统负担。
对于一个计算过程来说,关联数组可以维护它所需的一切参考,所有的数据性质都可以表述为关联数组与其存取的性质。我们称这一运算所需的参考为上下文环境。上下文是保证一个运算具有确定性的主要方式,换言之,它相当于语言中的语用这一要素。
如果一个过程能够产生比调用语句存活得更久的数据实体,则称该过程为类、该数据实体为对象。
—《结构程序设计》
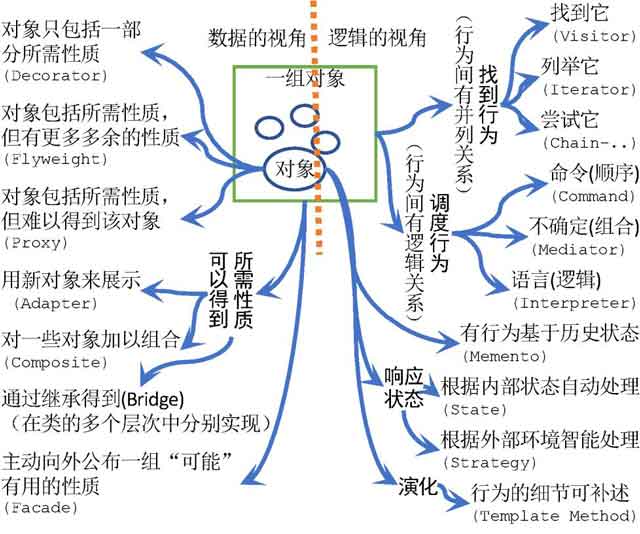
所谓模式的结构型与行为型,其实是从数据与逻辑的视角观察一组对象或一个对象的结果;而所谓模式,是对上述观察所见关系的一种抽象描述。GoF模式本质上是“结构(逻辑+数据)”这样的基本模型作用于数据间关系之后的产出。
对于应用开发中的功能性需求(计算需求与应用需求)来说,一切空间因素所致的复杂性,都可以通过组织形式来解决;一切时间因素所致的复杂性,都可以通过抽象模型来解决。
应用开发语言中有着两个发展方向:一个是从“模块/单元”这一角度出发的软件复用,另一个是从“项目/工程”这一角度出发的工程组织。模块划分永远不存在最优方案,模块化的精髓不在于外在形式的分离,而在于内在逻辑的延续。我们可以设定一个简单的分类依据,使得位于同一个单元中的函数表现出一定的相似性;我们可以使得一个单元或多个单元中的函数存有某种逻辑关系。
一个“建模者”所面临的需求主要来自三个方面:决策域、产品域与实施域。敏捷工程本质上是把决策域与产品域中的需求拉到了实施域中,就地决策与设计(产品),并将这一过程开放给用户。原型是轻量级的试错,它并没有减少问题的总量,但是“可讨论对象”(即原型)变成了纯粹用于工程师与用户之间沟通的桥梁。
从实施推进的角度来看,模型事实上允许我们将系统拆分成多个阶段,并尽早地预期了系统的每个阶段所依赖的(前一个阶段的、可能的)事实基础,因此模型具有可描述、可分析、可预期等性质。
系统应付规模问题的总法则只有两个:运算能力的分布,以及运算对象的分布。
“分割”是指一个问题集(无论是运算能力还是运算对象)能否被切分,而“分布”,指的是分割的结果能否被各个独立地加以处理。“可拆分”与拆分的结果“可处理”,这两个特性在“分布”中缺一不可。
如果子函数可以分布,则整个系统是可以分布的。逻辑或数据的时序依赖,在时间维度下不可分解,这预示着必然存在无法通过“分布(或组织的结构化)”来解决的规模/复杂性系统问题。而逻辑的不可分布并非无解,它最终可以被聚焦于“用于处理数据依赖问题的逻辑”的复杂性。
数据(x)的全集 = 数据(x') + 操作(x") + 状态(Sx)
数据依赖在概念上只表明多个逻辑作用于同一个数据,它最终将被表达为面向{ x', x", Sx }的操作,其中{x', x"}表明被依赖的数据与其可确定的行为,而{ Sx }表明一个有明确含义与可操作性的状态。
状态与消息的抽象概念的区别在于:前者往往带有位置之于存储,或数据之于逻辑的含义;后者则将位置与逻辑含义都抽取掉,只认为消息是一个约定所需的数据部分。
在大型系统(以及任何一个需要架构的系统)中,我们得承认两点事实:其一,我们的系统永远都只是更大系统的局部;其二,我们只能在实施中关注可控领域中的可控因素。任何一个子系统——作为一个更大系统的组成部件——对外部系统只需要承担这样两种责任:一,维护可对外公示的状态,使得外部系统可以将明确的行为(逻辑)施于自身;二,接受外部的消息,使得外部可以通过传递数据来影响自身。
“系统”这个规模是包含“应用”的,这一规模的定义本身就是由跨领域引申而来。系统本身的复杂性并不是由这些领域带来的,领域间的交叉与交互才是系统规模问题的根源。
作为组成部件的领域提供了一组接口:
将领域问题转义为一组逻辑的界面;
将领域间有无关系,转义为“领域对领域(调用者与被调用者)”的接口是否可达;
屏蔽领域内的数据性质,迫使开发者必须通过特定的设计来解决领域间的数据问题(例如数据类型、数据依赖等)。
系统与子系统之间面临的第一个问题,是系统的整体部署。系统的部署方案几乎决定或限制了大多数有关系统的决策,其中首当其冲的是数据的结构化与预结构化问题。数据的结构化阶段离处理阶段越远,其系统的整体收益也就越高,即数据要“尽可能早地”结构化。但结构化是一个逻辑过程,需要相应的部署环节的支持。
对于数据规划,关系型数据库强调数据项(Rows)间存在序列关系,以及数据列(Cols)间存在的键关系。在NoSQL的思维方式中,数据是通过一大批获取过程、在一系列被分布的数据中“收集”而最终得到的一个结果集。