在社会演化中,没有什么是不可避免的,使其成为不可避免的,是思想。
找到真正的瓶颈的所在位置,去提升它。
本书的精髓是——Scrapy的配置、事件、以及性能调优。
Scrapy是一个Twisted应用,使用单线程、非阻塞(异步)代码实现并发。只有了解事件驱动的机制,才能更好地理解本书——将阻塞代码转换为非阻塞代码,让瓶颈位于下载器中。
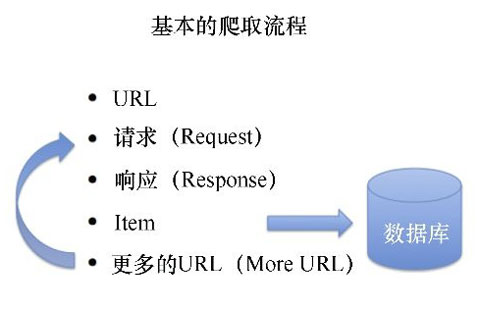
基于Scrapy框架的爬虫应用,其开发流程是UR2IM。
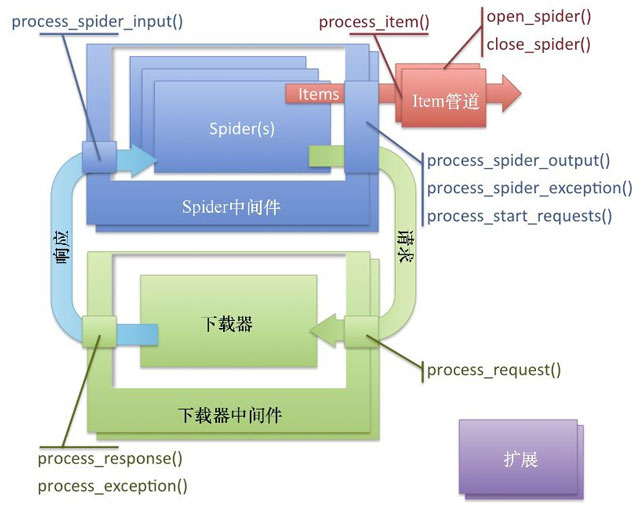
DownloaderMiddleware、SpiderMiddleware、Pipeline中的钩子方法。
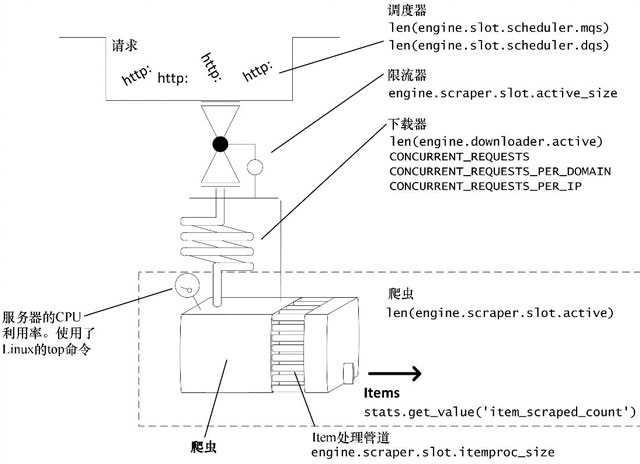
Scrapy在设计时就将下载器作为瓶颈。从一个低数值的CONCURRENT_REQUESTS开始,逐渐增加,直到触及下述限制之一:
CPU使用率大于80%~90%;
源网站延迟过度增长;
抓取程序中响应达到了5MB的内存限制。
同时,执行以下操作:
始终保持调度器队列(mqs/dqs)中至少有一定量的请求,避免下载器出现URL饥饿;
永远不要使用任何阻塞代码或CPU密集型代码。